E0;nh mang đến m&#x
E1;y Mac Excel đến web Excel 2021 Excel 2021 for Mac Excel 2019 Excel 2019 for Mac Excel 2016 Excel năm 2016 for Mac Excel 2013 Excel 2010 Excel 2007 Excel for Mac 2011 Excel Starter 2010 xem th&#x
EA;m...&#x
CD;t hơn
Mô tả
Hàm LINEST tính toán các thống kê mang lại một đường thẳng bằng cách dùng phương pháp "bình phương nhỏ nhất" để tính toán đường thẳng phù hợp nhất với dữ liệu của bạn, rồi trả về một mảng tế bào tả đường thẳng đó. Bạn cũng có thể kết hợp hàm LINEST với các hàm khác để tính toán thống kê cho các kiểu mô hình khác là đường tuyến tính trong các tham số không biết, bao gồm chuỗi nhiều thức, lô-ga-rit, hàm mũ và lũy thừa. Vì hàm này trả về một mảng giá trị, vì vậy nó phải được nhập vào dưới dạng công thức mảng. Có các hướng dẫn ở sau các ví dụ trong bài viết này.
Bạn đang xem: Công cụ dự đoán ngẫu nhiên
Phương trình của đường thẳng là:
y = mx + b
–hoặc–
y = m1x1 + m2x2 + ... + b
nếu có nhiều phạm vi giá trị x, khi mà giá trị y phụ thuộc là một hàm của các giá trị x độc lập. Giá trị m là các hệ số tương ứng với mỗi giá trị x và b là giá trị hằng số. Lưu ý rằng y, x và m có thể là các véc-tơ. Mảng mà hàm LINEST trả về là mn,mn-1,...,m1,b. Hàm LINEST cũng có thể trả về các thống kế hồi quy bổ sung.
Cú pháp
LINEST(known_y"s,
Cú pháp hàm LINEST có những đối số sau đây:
Cú pháp
known_y"s Bắt buộc. Tập giá trị y mà bạn đã biết trong quan lại hệ y = mx + b.
Nếu phạm vi của known_y"s nằm vào một cột đối kháng lẻ, thì mỗi cột của known_x"s được hiểu là một biến số riêng biệt rẽ.
Nếu phạm vi của known_y"s nằm vào một hàng 1-1 lẻ, thì mỗi hàng của known_x"s được hiểu là một biến số riêng rẽ.
known_x"s Tùy chọn. Tập giá trị x mà bạn có thể đã biết trong quan tiền hệ y = mx + b.
Phạm vi của known_x"s có thể bao gồm một hoặc nhiều tập biến số. Nếu chỉ dùng một biến số, thì known_y"s và known_x"s có thể là các phạm vi với bất kỳ hình dạng nào, miễn là chúng có các kích thước bằng nhau. Nếu dùng nhiều biến số, thì known_y"s phải là một véc-tơ (có nghĩa là một phạm vi cao một hàng và rộng một cột).
Nếu known_x"s được bỏ qua, thì nó được giả định là một mảng 1,2,3,... Có cùng kích thước như known_y"s.
const Tùy chọn. Một giá trị lô-gic chỉ rõ có bắt buộc hằng số b phải bằng 0 tuyệt không.
Nếu const là TRUE hoặc được bỏ qua, thì b được tính toán bình thường.
Nếu const là FALSE, thì b được đặt bằng 0 và giá trị m được điều chỉnh để phù hợp với y = mx.
stats Tùy chọn. Giá trị lô-gic chỉ rõ có trả về các thống kê hồi quy bổ sung hay không.
Nếu stats là TRUE, thì cực hiếm linest trả về những thống kê hồi quy ngã sung; bởi đó, mảng được trả về là mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey; F,df;ssreg,ssresid.
Nếu stats là FALSE hoặc được bỏ qua, thì hàm LINEST chỉ trả về hệ số m và hằng số b.
Các thống kê hồi quy bổ sung như sau.
| se1,se2,...,sen | Giá trị lỗi chuẩn chủa các hệ số m1,m2,...,mn. |
| seb | Giá trị lỗi chuẩn của hằng số b (seb = #N/A khi const là FALSE). |
| r2 | Hệ số xác định. So sánh các giá trị y ước tính và thực tế và nằm trong phạm vi giá trị từ 0 tới 1. Nếu nó là 1, thì có một đối sánh tương quan hoàn hảo trong mẫu — ko có sự khác biệt nào giữa giá trị y ước tính và giá trị y thực tế. Ở thái cực ngược lại, nếu hệ số xác định là 0, thì phương trình hồi quy không còn hữu ích vào việc dự đoán giá trị y. Để biết cách tính toán2, hãy xem mục "Ghi chú" ở trong phần sau nội dung bài viết này. |
| sey | Lỗi chuẩn mang đến ước tính y. |
| F | Thống kê F, hoặc giá trị F quan liêu sát được. Dùng thống kê F để xác định xem quan tiền hệ quan liêu sát được giữa các biến số độc lập và phụ thuộc có ngẫu nhiên xảy ra không. |
| df | Bậc tự do. Dùng bậc tự bởi để giúp bạn tìm giá trị F tới hạn trong bảng thống kê. So sánh các giá trị bạn tìm thấy trong bảng với thống kê F mà hàm LINEST trả về để xác định mức độ tin cậy của mô hình. Để tìm hiểu cách tính toán df, hãy coi mục "Ghi chú" ở phần sau bài viết này. Ví dụ 4 nói về cách dùng F và df. |
| ssreg | Tổng bình phương hồi quy. |
| ssresid | Tổng bình phương thặng dư. Để biết cách tính toán ssreg và ssresid, hãy xem mục "Ghi chú" ở phần sau bài viết này. |
Minh họa dưới đây cho thấy thứ tự mà các thống kê hồi quy bổ sung được trả về.

Chú thích
Bạn có thể mô tả bất kỳ đường thẳng nào bằng độ dốc và giao cắt y:
Độ dốc (m): Để search độ dốc của một con đường thẳng, thường được viết là m, lấy hai điểm trên đường thẳng đó, (x1,y1) cùng (x2,y2); độ dốc bằng (y2 - y1)/(x2 - x1).
Cắt Y (b): cắt chéo y của một đường thẳng, thường được viết là b, là quý hiếm của y tại điểm mà lại đường thẳng cắt trục y.
Phương trình của đường thẳng là y = mx + b. Khi đã biết giá trị của m và b, bạn có thể tính toán bất kỳ điểm nào trên đường thẳng bằng cách nhập giá trị y hoặc y vào phương trình đó. Bạn cũng có thể dùng hàm TREND.
Khi bạn chỉ có một biến độc lập x, bạn có thể tìm được độ dốc và giá trị giao cắt y trực tiếp bằng cách dùng công thức sau đây:
Độ dốc: =INDEX(LINEST(known_y"s,known_x"s),1)
Cắt Y: =INDEX(LINEST(known_y"s,known_x"s),2)
Độ chính xác của đường thẳng vì hàm LINEST tính toán phụ thuộc vào độ phân tán trong dữ liệu của bạn. Dữ liệu càng tuyến tính, thì tế bào hình LINEST càng chính xác. Hàm LINEST dùng phương pháp bình phương nhỏ nhất để xác định sự phù hợp nhất của dữ liệu. Lúc bạn chỉ có một biến số độc lập x, thì các phép tính mang đến m và b dựa vào công thức sau đây:
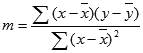
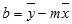
trong đó x và y là các trung độ mẫu, tức là x = AVERAGE(known x"s) và y = AVERAGE(known_y"s).
Các hàm phù hợp với đường thẳng và đường cong LINEST và LOGEST có thể tính toán đường thẳng hoặc đường cong hàm mũ phù hợp nhất với dữ liệu của bạn. Tuy nhiên, bạn phải quyết định kết quả nào trong hai kết quả là phù hợp nhất với dữ liệu của mình. Bạn có thể tính toán TREND(known_y"s,known_x"s) mang lại một đường thẳng, hoặc GROWTH(known_y"s, known_x"s) cho một đường cong hàm mũ. Những hàm này, không có đối số new_x"s, trả về một mảng giá trị y được dự đoán dọc theo đường thẳng hoặc đường cong tại điểm dữ liệu thực của bạn. Sau đó, bạn có thể so sánh giá trị dự đoán với giá trị thực tế. Bạn có thể muốn vẽ đồ thị cho cả nhì để có được so sánh trực quan.
Trong phân tích hồi quy, Excel tính toán tại mỗi điểm bình phương của hiệu số giữa giá trị y ước tính mang đến điểm đó và giá trị y thực tế của điểm đó. Tổng của các bình phương hiệu này được gọi là tổng bình phương thặng dư, ssresid. Sau đó, Excel tính toán tổng cộng bình phương, sstotal. Khi đối số const = TRUE hoặc được bỏ qua, thì tổng cộng bình phương là tổng của các bình phương hiệu giữa giá trị y thực tế và bình quân các giá trị y. Lúc đối số const = FALSE, thì tổng cộng bình phương là tổng các bình phương của các giá trị y thực tế (mà ko trừ giá trị y trung bình ra khỏi mỗi giá trị y). Sau đó có thể tìm thấy tổng bình phương hồi quy, ssreg từ công thức ssreg = sstotal - ssresid. Tổng bình phương thặng dư càng nhỏ so với tổng cộng những bình phương, thì quý hiếm của thông số xác định, r2, cànglớn, mà đây là một chỉ báo cho biết thêm phương trình kết quả của phân tích hồi quy biểu thị rõ mang lại đâu mối quan hệ giữa những biến số. Quý hiếm của r2 bởi ssreg/sstotal.
Giá trị của df được tính toán như sau, lúc không có cột X nào được loại bỏ khỏi tế bào hình bởi vì tính cộng tuyến: nếu có các cột k chứa known_x’s và const = TRUE hoặc được bỏ qua, thì df = n – k – 1. Nếu const = FALSE, thì df = n - k. Trong cả hai trường hợp, cột X đã được loại bỏ vày tính cộng tuyến sẽ làm tăng giá trị của df thêm 1.
Khi nhập một hằng số mảng (chẳng hạn như known_x"s) làm đối số, bạn hãy dùng dấu phẩy để phân tách các giá trị chứa vào cùng một hàng và dùng dấu chấm phẩy để phân tách hàng. Ký tự phân tách có thể khác nhau tùy thuộc vào thiết đặt vùng của bạn.
Hãy lưu ý rằng các giá trị y mà phương trình hồi quy dự đoán có thể không hợp lệ nếu chúng nằm ngoài phạm vi các giá trị y mà bạn dùng để xác định phương trình.
Thuật toán ẩn dưới dùng vào hàm LINEST khác với thuật toán ẩn dưới dùng trong các hàm SLOPE và INTERCEPT. Sự khác nhau giữa các thuật toán này có thể dẫn đến các kết quả khác nhau khi dữ liệu không được xác định và cộng tuyến. Ví dụ, nếu các điểm dữ liệu của đối số known_y"s là 0 và các điểm dữ liệu của đối số known_x"s là 1:
Hàm LINEST trả về giá trị 0. Thuật toán của hàm LINEST được thiết kế để trả về kết quả hợp lý của dữ liệu cộng tuyến và vào trường hợp này, có thể tìm thấy ít nhất một câu trả lời.
Hàm SLOPE và INTERCEPT trả về giá trị lỗi #DIV/0! lỗi. Thuật toán của hàm SLOPE và INTERCEPT được thiết kế để chỉ tìm kiếm một câu trả lời và trong trường hợp này có thể có nhiều câu trả lời.
Ngoài việc dùng hàm LOGEST để tính toán các thống kê hoặc các kiểu hồi quy khác, bạn có thể dùng hàm LINEST để tính toán một phạm vi các kiểu hồi quy khác bằng cách nhập các hàm của các biến số x làm các chuỗi x và y cho hàm LINEST. Ví dụ, công thức sau đây:
=LINEST(yvalues, xvalues^COLUMN($A:$C))
hoạt động lúc bạn có một cột đơn các giá trị y và một cột solo các giá trị x cần tính toán phép xấp xỉ lập phương (đa thức lũy thừa bậc 3) của biểu mẫu:
y = m1*x + m2*x^2 + m3*x^3 + b
Bạn có thể điều chỉnh công thức này để tính toán các kiểu hồi quy khác, nhưng trong một số trường hợp nó đòi hỏi phải điều chỉnh giá trị đầu ra và các thống kê khác.
Ví dụ
Ví dụ 1 - Độ dốc và giao cắt Y
Sao chép tài liệu của lấy ví dụ như trong bảng dưới đây và ốp lại ô A1 của một trang tính Excel mới. Để cách làm hiển thị kết quả, hãy lựa chọn chúng, nhận F2 và kế tiếp nhấn Enter. Nếu như cần, bạn cũng có thể điều chỉnh độ rộng cột nhằm xem tất cả dữ liệu.
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| Kết quả (độ dốc) | Kết quả (giao cắt y) |
| 2 | 1 |
| Công thức (công thức mảng vào ô A7:B7) | |
| =LINEST(A2:A5,B2:B5,,FALSE) |
Ví dụ 2: Hồi quy Tuyến tính Đơn giản
Sao chép dữ liệu của lấy một ví dụ trong bảng tiếp sau đây và ốp lại ô A1 của một trang tính Excel mới. Để bí quyết hiển thị kết quả, hãy lựa chọn chúng, thừa nhận F2 và tiếp nối nhấn Enter. Nếu cần, chúng ta cũng có thể điều chỉnh độ rộng cột để xem tất cả dữ liệu.
| 1 | $3.100 |
| 2 | $4.500 |
| 3 | $4.400 |
| 4 | $5.400 |
| 5 | $7.500 |
| 6 | $8.100 |
| Công thức | Kết quả |
| =SUM(LINEST(B1:B6, A1:A6)*9,1) | $11.000 |
| Tính toán ước tính doanh số bán hàng vào thời điểm tháng thứ chín, dựa bên trên doanh số các mon từ 1 đến 6. |
Ví dụ 3: Hồi quy Tuyến tính Đa biến
Sao chép tài liệu của ví dụ như trong bảng sau đây và dán lại ô A1 của một trang tính Excel mới. Để bí quyết hiển thị kết quả, nên chọn lựa chúng, dấn F2 và tiếp nối nhấn Enter. Giả dụ cần, bạn có thể điều chỉnh độ rộng cột để xem tất cả dữ liệu.
| 2310 | 2 | 2 | 20 | $142.000 |
| 2333 | 2 | 2 | 12 | $144.000 |
| 2356 | 3 | 1,5 | 33 | $151.000 |
| 2379 | 3 | 2 | 43 | $150.000 |
| 2402 | 2 | 3 | 53 | $139.000 |
| 2425 | 4 | 2 | 23 | $169.000 |
| 2448 | 2 | 1,5 | 99 | $126.000 |
| 2471 | 2 | 2 | 34 | $142.900 |
| 2494 | 3 | 3 | 23 | $163.000 |
| 2517 | 4 | 4 | 55 | $169.000 |
| 2540 | 2 | 3 | 22 | $149.000 |
| -234,2371645 | ||||
| 13,26801148 | ||||
| 0,996747993 | ||||
| 459,7536742 | ||||
| 1732393319 | ||||
| Công thức (công thức mảng cồn được nhập vào ô A19) | ||||
| =LINEST(E2:E12,A2:D12,TRUE,TRUE) |
Ví dụ 4: áp dụng Thống kê F và r2
Trong lấy một ví dụ trên đây, thông số xác định,hay r2, là 0,99675 (xem ô A17 trong tác dụng của đối số LINEST), diễn tả một quan lại hệ mạnh mẽ giữa các biến số chủ quyền và giá bán bán. Bạn có thể dùng thống kê F để xác định xem những kết quả này, với giá trị r2 cao như vậy, có ngẫu nhiên xảy ra hay không.
Giả sử rằng bên trên thực tế ko có quan lại hệ nào giữa các biến số, nhưng mà bạn đã lấy một mẫu hiếm gặp về 11 tòa cao ốc văn phòng, khiến đến phân tích thống kê thể hiện một quan lại hệ mạnh mẽ. Thuật ngữ "Alpha" được dùng để chỉ xác xuất của kết luận không đúng lầm rằng có một quan lại hệ.
Có thể cần sử dụng giá trị F với df trong đầu ra từ hàm LINEST để review khả năng xảy ra giá trị F cao hơn. Có thể so sánh F với mức giá trị tới hạn trong bảng phân bố F đã desgin hoặc hàm FDIST vào Excel để giám sát và đo lường xác suất của giá trị F to hơn mở ra tình cờ. Phân bổ F tương thích có bậc thoải mái v1 với v2. Trường hợp n là số điểm tài liệu và const = TRUE hoặc được bỏ qua thì v1 = n – df – 1 và v2 = df. (Nếu const = FALSE thì v1 = n – df và v2 = df.) Hàm FDIST — cùng với cú pháp FDIST(F,v1,v2) — đang trả về xác suất của quý hiếm F cao hơn xuất hiện thêm tình cờ. Trong lấy một ví dụ này, df = 6 (ô B18) cùng F = 459,753674 (ô A18).
Giả sử cực hiếm Alpha là 0,05, v1 = 11 – 6 – 1 = 4 với v2 = 6, mức đặc biệt của F là 4,53. Do F = 459,753674 cao hơn nhiều đối với 4,53, hết sức khó có chức năng xảy ra giá trị F cao mang lại vậy. (Với Alpha = 0,05, đưa thiết rằng không tồn tại mối dục tình nào giữa mức quan hệ tình dục của known_y và của known_x là bị phủ nhận khi F vượt quá mức giới hạn, 4,53.) chúng ta có thể dùng hàm FDIST trong Excel để có được xác suất giá trị F cao tới cả này vì vô tình xảy ra. Ví dụ, FDIST(459,753674, 4, 6) = 1,37E-7, một phần trăm cực nhỏ. Bạn cũng có thể kết luận, bằng phương pháp tìm mức tới hạn F vào bảng hoặc bằng cách dùng hàm FDIST, rằng phương trình hồi quy có ích trong việc dự kiến giá trị định giá của những cao ốc văn phòng và công sở trong khu vực này. Hãy hãy nhờ rằng điều đặc biệt quan trọng là sử dụng những giá trị đúng của v1 với v2 được đo lường trong đoạn văn trước đó.
Ví dụ 5: Tính toán thống kê t-Statistics
Một kiểm tra giả thuyết khác sẽ xác định xem mỗi hệ số độ dốc có hữu ích ko trong việc ước tính giá trị định giá của một cao ốc văn phòng vào Ví dụ 3. Ví dụ, để kiểm tra hệ số tuổi thọ mang đến ý nghĩa thống kê, hãy chia -234,24 (hệ số độ dốc tuổi thọ) đến 13,268 (lỗi chuẩn ước tính của hệ số tuổi thọ vào ô A15). Dưới phía trên là giá trị t-quan sát:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Nếu giá trị tuyệt đối của t đủ lớn, thì có thể kết luận rằng hệ số độ dốc là hữu ích vào việc ước tính giá trị định giá của một cao ốc văn phòng trong Ví dụ 3. Bảng dưới đây thể hiện giá trị tuyệt đối của 4 giá trị t-quan sát.
Nếu bạn tham khảo bảng vào sổ tay thống kê, bạn sẽ thấy rằng t-tới hạn, hai phía, với 6 bậc tự vày và Alpha = 0,05 là 2,447. Cũng có thể tìm được giá trị tới hạn này bằng cách dùng hàm TINV trong Excel. TINV(0,05,6) = 2,447. Vì giá trị tuyệt đối của t (17,7) lớn rộng 2,447, do đó tuổi thọ là một biến số quan lại trọng lúc ước tính giá trị định giá của một cao ốc văn phòng. Mỗi vào số các biến số độc lập khác có thể được kiểm tra ý nghĩa thống kê theo cách tương tự. Dưới phía trên là các giá trị t-quan sát mang lại mỗi biến số độc lập.
| Diện tích mặt sàn | 5,1 |
| Số lượng văn phòng | 31,3 |
| Số lượng cửa vào | 4,8 |
| Tuổi thọ | 17,7 |
Tất cả những giá trị này đều có giá trị tuyệt đối lớn rộng 2,447, vì vậy tất cả các biến số dùng vào phương trình hồi quy đều hữu ích vào việc dự đoán giá trị định giá của các cao ốc văn phòng vào vùng này.
khóa đào tạo và huấn luyện Lập trình thiết kế C++ khóa đào tạo và huấn luyện lập trình C++ căn bản Phát sinh số bỗng dưng trong C++ (Random number generation)Dẫn nhập
Ở bài học trước, bản thân đã chia sẻ cho chúng ta về TỪ KHÓA BREAK & CONTINUE. Từ khóa break được dùng để dứt các vòng lặp while, do-while, for và câu đk switch. Từ khóa continue vẫn nhảy đến cuối vòng lặp hiện nay tại, cùng thực thi lần lặp tiếp theo.
Trong bài xích hôm nay, bản thân sẽ giới thiệu cho các bạn về cách thức Phát sinh số bỗng dưng trong C++ (Random number generation). Chúng ta có thể ứng dụng nó vào phần đông chương trình phải phát sinh số ngẫu nhiên, những trò chơi, hoặc để áp dụng vào những bài học về mảng tiếp theo.
Nội dung
Để gọi hiểu bài này xuất sắc nhất chúng ta nên có kỹ năng và kiến thức cơ phiên bản về:
Trong bài bác ta sẽ cùng tìm hiểu các vấn đề:
Tổng quan tiền về tạo ra số ngẫu nhiênPhát sinh số bất chợt trong C++Phát sinh số đột nhiên trong C++ 11
Tổng quan lại về phát sinh số ngẫu nhiên
Phát sinh các số ngẫu nhiên được ứng dụng không ít trong lập trình, nhất là trong những trò chơi, các chương trình cần dữ liệu ngẫu nhiên, ….
Ví dụ về trò chơi bắn máy bay, nếu như nó không tồn tại những sự khiếu nại ngẫu nhiên, phần đông máy bay sẽ luôn luôn luôn lộ diện cùng 1 vị trí, tiến công bạn theo cùng một cách, đều vật thể xuất hiện thêm trên mặt đường không lúc nào thay đổi, vv ... Và đó ko phải là 1 trong những trò chơi hay.
Trong cuộc sống, chúng ta thường tạo nên số ngẫu nhiên bằng phương pháp như rung lắc 1 con xúc xắc, rút 1 lá thăm, tung 1 đồng xu, … và không ít vấn đề hốt nhiên trong cuộc sống thường ngày khác.
Trong lập trình, phần đông thứ hồ hết được làm cho từ 2 số 0 với 1, chỉ bao gồm đúng hoặc sai, không có trường đúng theo ở giữa. Máy vi tính không thể lắc 1 nhỏ xúc xắc, rút 1 lá thăm, tung 1 đồng xu, … tác dụng mà nó chuyển ra, luôn luôn là kết quả có thể dự đoán trước, lấy ví dụ 1 + 1 luôn luôn là 2, không thể là 1 trong giá trị khác.
Vì vậy, các máy tính xách tay không có công dụng tạo ra số ngẫu nhiên. Mong tạo số ngẫu nhiên, lập trình sẵn viên phải tự phát hành 1 hệ thống phát sinh số ngẫu nhiên.
Phát sinh số ngẫu nhiên là một vấn đề rất cần thiết trong lập trình, để thỏa mãn nhu cầu nhu mong đó, C++ đã xây cất sẵn một số thuật toán tạo nên số ngẫu nhiên.
Phát sinh số hốt nhiên trong C++
Ngôn ngữ C++ cung cấp 2 hàm có tính năng khởi tạo ra và tạo ra số ngẫu nhiên, 2 hàm này thuộc thư viện cstdlib:
Khởi sản xuất số bỗng dưng (initialize random number generator)
Để khởi tạo ra số ngẫu nhiên, bạn áp dụng hàm srand() thuộc thư viện cstdlib:
void srand(unsigned int seed);
Lưu ý:
Hàm srand() nhận vào một trong những đối số kiểu số nguyên không dấu, được call là seed (hạt giống).Với từng seed khác nhau, hàm srand() sẽ khởi tạo ra những bộ số thốt nhiên khác nhau. Rất nhiều số đột nhiên này đang được mang ra bởi hàm rand().Hai khởi tạo thành số ngẫu nhiên khác nhau với cùng một seed sẽ tạo ra và một kết quả.Chỉ nên được gọi hàm srand() 1 lần trước khi phát sinh số ngẫu nhiên.Kết quả gây ra số hốt nhiên của hàm rand() dựa vào vào giá trị của seed (hạt giống), nếu những lần khởi tạo ra đều sử dụng cùng 1 seed, những số tự nhiên nhận được đã là như nhau.
Vì vậy, quý giá của seed (hạt giống) cũng phải là một số ngẫu nhiên trong những lần truyền vào hàm srand(). Nghe có vẻ khá mâu thuẩn, bọn họ đang cần một số ngẫu nhiên để tạo ra các số ngẫu nhiên. Vậy, vấn đề là fan ta yêu cầu tìm ra 1 số chuyển đổi mỗi khi chương trình được chạy, chưa phải là số do người tiêu dùng chọn.
Một phương án cho vấn đề này là dựa trên thời hạn hệ thống. Các lần chương trình được chạy, thời gian sẽ không giống nhau. Nên tín đồ ta lấy quý hiếm thời gian khối hệ thống làm seed (hạt giống), tác dụng sẽ là phần đông số ngẫu nhiên khác nhau trong những lần chạy chương trình.
Để rước được thời hạn từ hệ thống, chúng ta có thể sử dụng hàm time() trực thuộc thư viện ctime. Hàm này sẽ trả về số giây từ bỏ 00:00 giờ, ngày 01 tháng 1 năm 1970.
Ví dụ:
#include #include // for rand() và srand()#include // for time()using namespace std;int main()// initialize random number generatorsrand(time(0)); // mix initial seed value lớn system clock// generate random number// ...return 0;Ví dụ trên chỉ mới khởi sản xuất số đột nhiên từ thời hạn hệ thống, cách phát sinh các số đột nhiên sẽ được reviews ở phần tiếp theo.
Phát sinh số bỗng nhiên (generate random number)
Để phát sinh 1 số ngẫu nhiên, bạn thực hiện hàm rand() trực thuộc thư viện cstdlib:
int rand(void);
int rand(void);Lưu ý:
Hàm rand() trả về một số nguyên ngẫu nhiên trong khoảng từ 0 đến RAND_MAX.RAND_MAX là 1 trong những hằng số có giá trị 32767, được có mang trong thư viện cstdlib.Ví dụ về tạo ra số ngẫu nhiên:
int v1 = rand();// v1 in the range 0 khổng lồ 32767int v2 = rand() % 100;// v2 in the range 0 khổng lồ 99int v3 = rand() % 100 + 1;// v3 in the range 1 khổng lồ 100int v4 = rand() % 30 + 1985;// v4 in the range 1985-2014Một số lấy một ví dụ về phát sinh số ngẫu nhiên
Ví dụ về trò nghịch đoán số từ là 1 số gây ra ngẫu nhiên:
#include #include // for rand() và srand()#include // for time()using namespace std;int main(){int n
Secret, n
Guess;// initialize random seedsrand(time(NULL));// generate secret number between 1 and 10n
Secret = rand() % 10 + 1;do {cout > n
Guess;if (n
Secret n
Guess) cout Output:
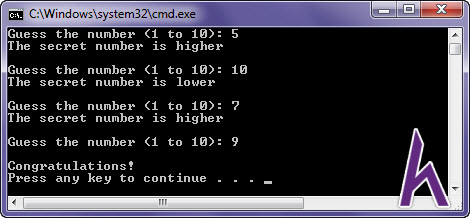
Chương trình trên vạc sinh một vài ngẫu nhiên từ là một đến 10, và yêu cầu người dùng lặp lại việc chọn một số làm thế nào cho trùng với số tình cờ của hệ thống.
Ví dụ tạo ra một dãy 10 chữ số ngẫu nhiên:
#include #include // for rand() and srand()#include // for time()using namespace std;int main(){srand(time(0)); // mix initial seed value to system clockfor (int count = 0; count Output:
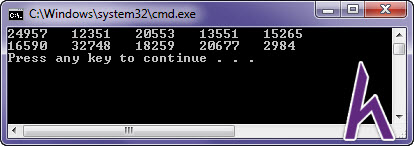
Phát sinh số đột nhiên trong C++ 11
C++ 11 cung cấp thêm rất nhiều thuật toán tạo ra số ngẫu nhiên thuộc tủ sách random.
Ví dụ về 1 thuật toán tạo ra số tự nhiên Mersenne Twister thường xuyên được sử dụng:
#include #include using namespace std;int main(){random_device rd;// only used once to initialize (seed) enginemt19937 rng(rd());// random-number engine used (Mersenne-Twister in this case)// output 10 random numberfor (int i = 0; i uni(1, 100);for (int i = 0; i Output:
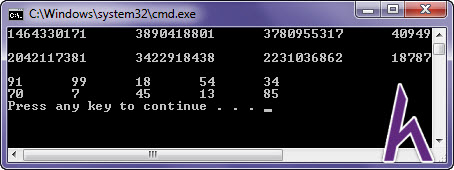
Thuật toán trên tạo nên các số nguyên không dấu 32 bit, nên sẽ sở hữu được phạm vi to hơn không ít so với sử dụng hàm rand(). Bạn cũng có thể sử dụng hình dáng mt19937_64 cho trở nên rng để có phạm vi số to hơn (64 bit).
Ví dụ trên có thực hiện từ khóa auto, chi tiết về nó sẽ tiến hành hướng dẫn trong bài xích TỪ KHÓA tự động TRONG C++ (The tự động keyword).
Vẫn còn không ít thuật toán phát sinh số bỗng nhiên khác, các bạn có thể tìm hiểu thêm và chia sẽ lại cho mọi người nhé.
Kết luận
Qua bài học kinh nghiệm này, các bạn đã nắm rõ về phương thức Phát sinh số bỗng nhiên trong C++ (Random number generation). Bạn cũng có thể ứng dụng nó vào mọi chương trình buộc phải phát sinh số ngẫu nhiên, những trò chơi, hoặc để áp dụng vào những bài học kinh nghiệm về mảng tiếp theo.
Trong bài tiếp theo, mình sẽ trình làng cho chúng ta về MẢNG 1 CHIỀU trong C++ (Arrays).
Cảm ơn các bạn đã theo dõi bài xích viết. Hãy nhằm lại bình luận hoặc góp ý của chính bản thân mình để phát triển bài viết tốt hơn. Đừng quên “Luyện tập – thách thức – không phải lo ngại khó”.
Xem thêm: Hà Nội Công Bố Số Lượng Đăng Ký Tuyển Sinh Lớp 10 Năm 2020 Hà Nội 2020
Thảo luận
Nếu bạn có bất kỳ khó khăn hay thắc mắc gì về khóa học, đừng ngần ngại đặt thắc mắc trong phần BÌNH LUẬN bên dưới hoặc trong mục HỎI và ĐÁP trên tủ sách trunghocthuysan.edu.vn.com để nhận được sự cung ứng từ cộng đồng.